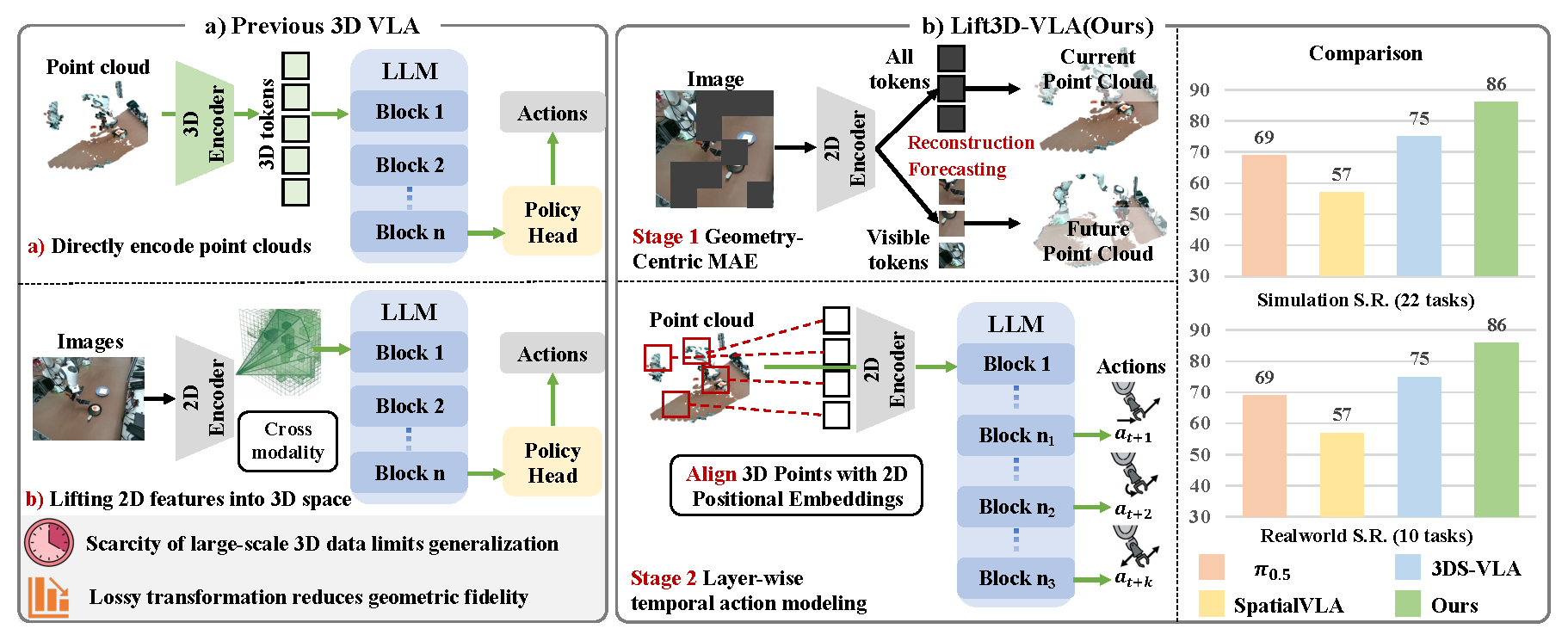
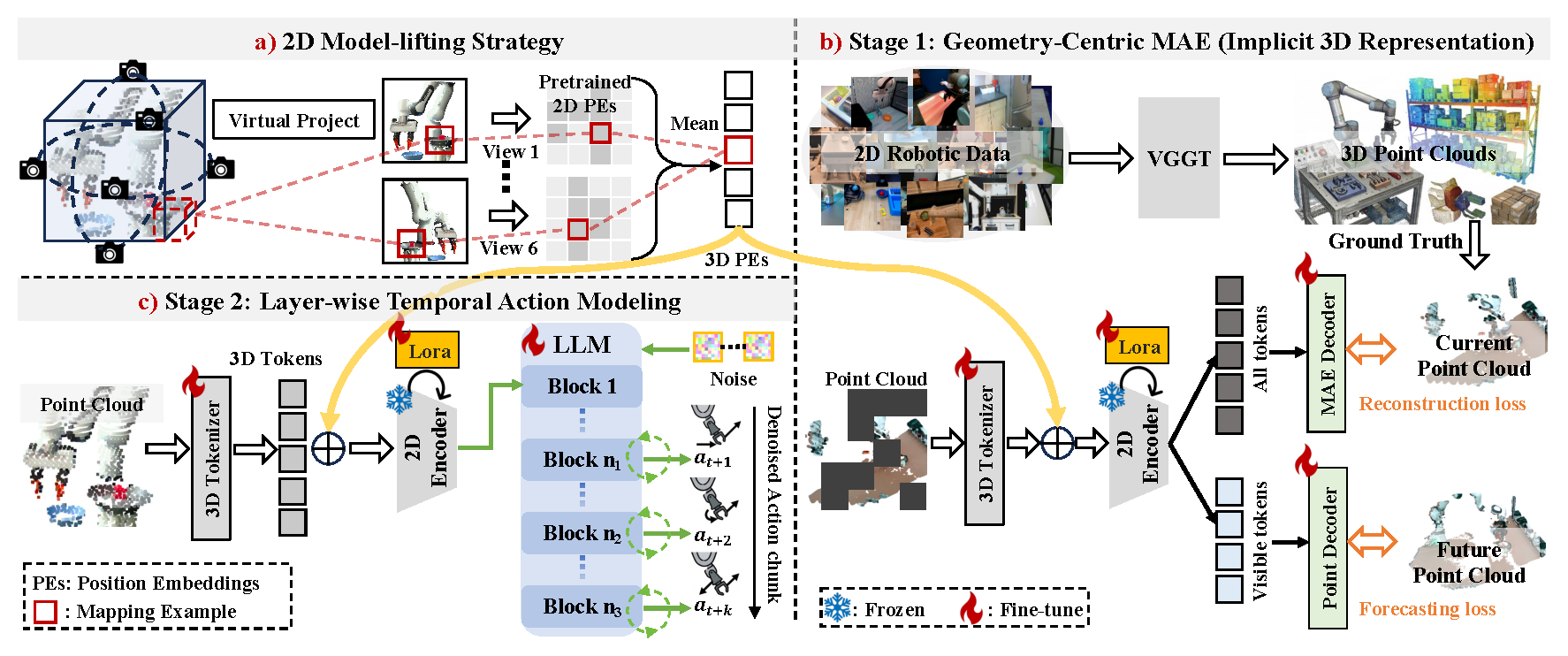
Recently, Vision–Language–Action (VLA) models have demonstrated strong generalization across diverse tasks. However, effective robotic manipulation in physical environments fundamentally requires geometric understanding and spatial reasoning. While some VLA approaches attempt to incorporate 3D information, they are constrained by limited data availability and geometric information loss in current 3D encoding pipelines, and fail to jointly capture 3D geometry and temporally structured actions in dynamic environments. To address these limitations, we introduce Lift3D-VLA, a unified VLA framework that equips models with explicit 3D point cloud reasoning and enables temporally coherent action generation. First, building upon our previous work Lift3D, an enhanced 2D model-lifting strategy is proposed to geometrically align 3D points with pretrained 2D positional embeddings, enabling direct point-cloud encoding within the VLA vision encoder while minimizing spatial information loss. Based on explicit 3D inputs, we propose Geometry-Centric Masked Autoencoding (GC-MAE), a dual-objective self-supervised framework that reconstructs the current point cloud while predicting its future geometric evolution, allowing the 2D vision encoder to internalize both 3D structure and physical dynamics. We further design layer-wise temporal action modeling, which leverages multiple layers of the LLM to collaboratively predict action chunks, enabling temporally consistent predictions.